转载知乎Erutan Lai
北京大学 计算机应用技术博士
这篇文章主要参考了国家自然科学基金的申请代码,以及ACL 2023的投稿领域分类,谈谈自然语言处理在人工智能中的位置,以及自然语言处理的主要研究方向。当然,疏漏在所难免,毕竟,自然语言处理这个题目太大了。
不了解人工智能和自然语言处理的,可以读这篇文章来了解下人工智能和自然语言处理到底在做 什么。初入⻔的同学也可以参考下来选择研究方向。
自然语言处理在人工智能中的位置
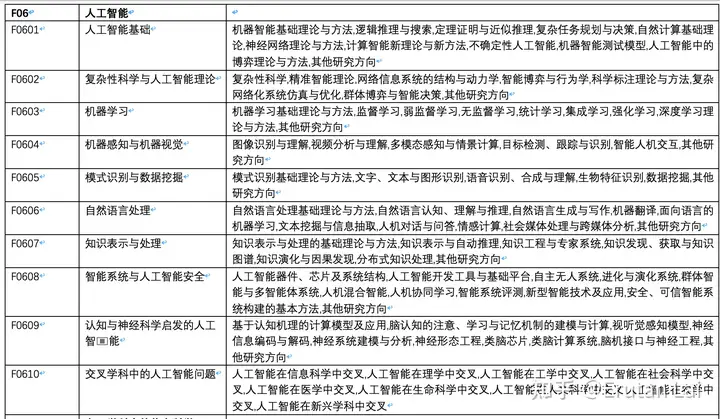
国家自然科学基金体系中,人工智能是信息科学部(F)下的第6个一级分类(F06)。信息科学部中,人工智能之外,还有6个研究方向,分别是:F01 电子学与信息系统,F02 计算机科学,F03 自动化,F04 半导体科学与信息器件,F05 光学和光电子,F07 交叉学科中的信息科学。
人工智能下分10个二级分类代码,分别为:
- 2个偏基础理论的:人工智能基础(F0601)与 复杂性科学与人工智能理论(F0602),主要研究一些基础理论,包括逻辑推理、不确定性、博弈理论、复杂系统优化与仿真、标注方法等。
- 5个不同的应用角度的,包括:
- F0603 机器学习:通用的机器学习方法,如监督\弱监督\无监督学习,集成学习,强化学习,深度学习理论等。
- F0604 机器感知与机器视觉:计算机视觉相关,包括图像的识别与理解,多模态,智能人机交互等。
- F0605 模式识别与数据挖掘:识别与挖掘规律,主要包括文字、图像、语音、生物特征的识别,以及数据挖掘、模式挖掘等。
- F0606 自然语言处理:语言理解、认知与生成,主要包括文本生成、机器翻译、信息抽取、人机对话与问答,情感计算等。
- F0607 知识表示与处理:侧重于知识的处理,包括知识表示、图谱构建、知识演化、自动推理、专家系统等。
- 3个交叉学科的,包括:智能系统与人工智能安全(F0608 系统、平台、安全与可信性),认知与神经科学启发的人工智能(F0609 强调认知科学带来的启发),交叉学科中的人工智能问题(F0610,其它交叉领域,如信息科学、理、工、生物、社会、农、医学等)
由此可见,自然语言处理研究的是针对语言的智能。自然语言处理更多关注文字。语音的识别与合成擦边,但更偏向模式识别(F0605),如果涉及更多的认知与理解也算自然语言处理。自然语言处理不太关注简单的文字间的模式挖掘(F0605)。自然语言处理关注字词句的语义、信息抽取、文本生成、人机交互(问答、对话)、社交媒体分析等。
自然语言处理的主要研究方向
上文提到,国家自然科学基金中,自然语言处理包括1个2级标题,10个具体方向。而像自然语言处理的顶级会议ACL的投稿方向中,自然语言处理被分为了26个领域315个方向。
幸福好不容易:自然语言处理(NLP)研究子方向——ACL 2023领域汇总93 赞同 · 3 评论文章
以下,我试图将ACL的25个领域(除了Theme Track)划分到国自然的10个领域中,谈一下自然语言处理主要在做什么。
一、自然语言处理基础理论与方法
- (十二)语言学理论、认知建模和心理语言学 (Linguistic Theories, Cognitive Modeling and Psycholinguistics)
这项中,认知建模和心理语言学,应该是属于“自然语言认知、理解与推理”的。
其实我觉得这是个口袋分类,只要是比较偏“通用”的“理论”都可以放到这个分类。
然而挺难找“通用”的理论的。很多理论我感觉更应该分到各自的场景中,比如词表示与句子建模相关的应该放到“自然语言认知、理解与推理”,预训练模型的理论分析相关的应该根据具体类型放到“自然语言理解”,“文本生成”或者“机器学习”。
基础理论相关的我并不太了解,以上只是“我认为”,并不准确。
二、自然语言认知、理解与推理
- (三)话语和语用学 (Discourse and Pragmatics)
- (十七)音系学、形态学和词语分割 (Phonology, Morphology and Word Segmentation)
- (二十)语义学:词汇层面 (Semantics: Lexical)
- (二十一)语义学:句级语义、文本推断和其他领域 (Semantics: Sentence-Level Semantics, Textual Inference and Other Areas)
- (二十五)句法学:标注、组块分析和句法分析 (Syntax: Tagging, Chunking and Parsing)
这里主要是俗称的“基础自然语言处理任务”,是在语言学的道路上,逐渐建构语义的过程。大致可以分为以下五个大类:
1. 词汇的语言学、形态学、音韵学、语义学相关。例如形态变化 (Morphological inflection),形态学分割 (Morphological segementation),词性还原 (Lemmatization),音系学 (Phonology),发音建模 (Pronunciation modeling),一词多义 (Polysemy),词汇关系 (Lexical relationships),词汇语义变迁 (Lexical semantic change)
2. 语义表示类:embedding/representation。用向量表示词汇、句子等,并满足一定的规律。比如子词表征 (Subword representations),词嵌入 (Word embeddings),短语和句子嵌入 (Phrase/sentence embedding)
3. 分块/标注类:chunking/sequence labeling,将文本(线性结构)分割成若干的块,然后对每块去做一个分类(label)。但还在语言学/语义学层面,没有到知识与信息抽取的程度。比如中文分割 (Chinese segmentation),词性标注 (Part-of-speech tagging)。
4. 解析类:Parsing,去解析文本(线性结构)中的单元(subword,词汇,句子等)之间的关系(一般是图)。比如回指/共指/桥接消解 (Anaphora/Coreference/Bridging resolution),依存/组合句法分析 (Dependency parsing, Constituency parsing), 话语分析 (Discourse parsing)。或者上述任务的延伸,如语义分析 (Semantic parsing),观点挖掘 (Argument mining)。
5. 句间关系类:在语言/语义层面判断句子间的关系,如语义相同、相似、蕴含等。比如同义句识别 (Paraphrase recognition)、文本蕴含 (Textual entailment)、自然语言推理 (Natural language inference)、文本语义相似性 (Semantic textual similarity)。或者上述任务的延伸,如同义句生成 (Paraphrase generation),文本简化 (Text simiplification),词和短语对齐 (Word/phrase alignment)。
以下从细粒度到粗粒度地对具体任务举例:
1.形态学分割 (Morphological segementation)
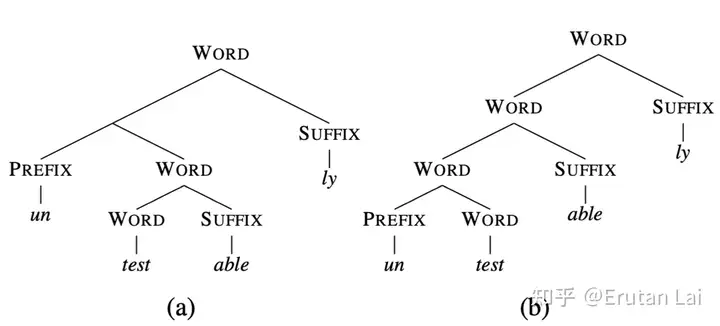
2.词性还原 (Lemmatization)

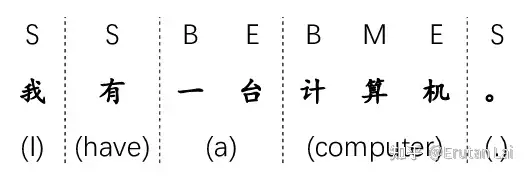
3. 中文分词 (Chinese segmentation)
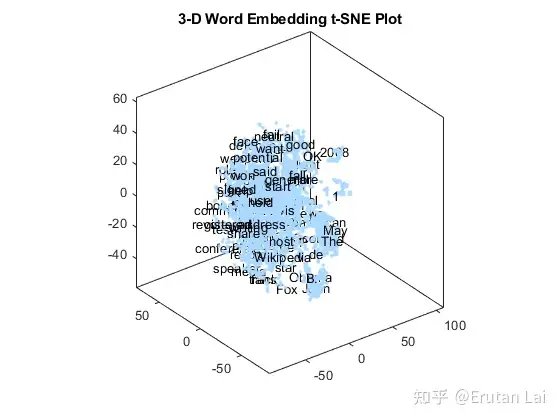
4.词嵌入 (Word embeddings)
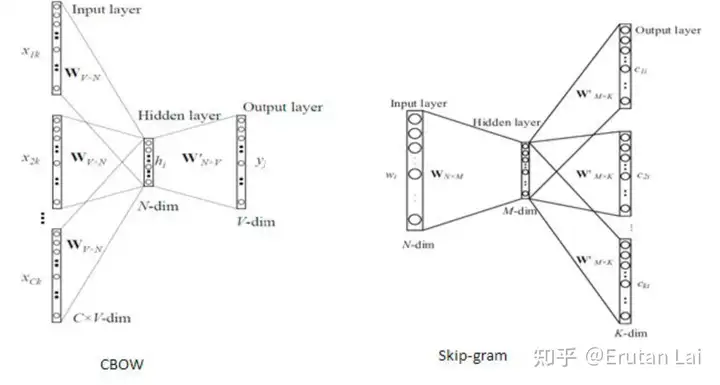
5.共指消解 (Coreference resolution)
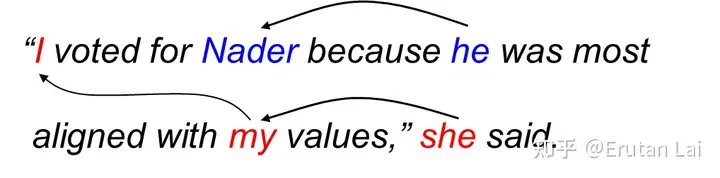
6.依存句法分析 (Dependency parsing)
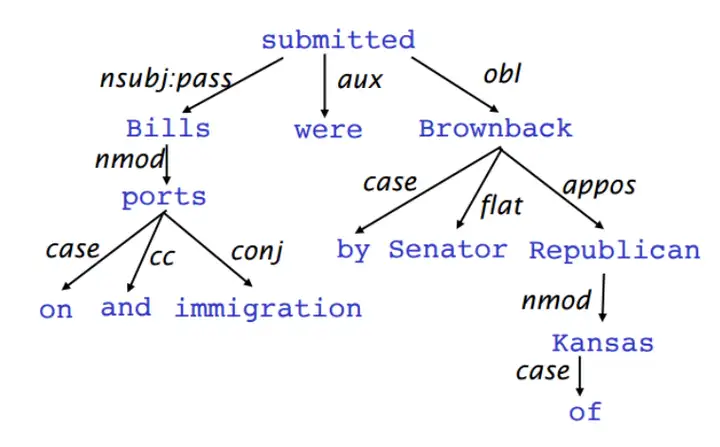
7.自然语言推理 (Natural language inference)
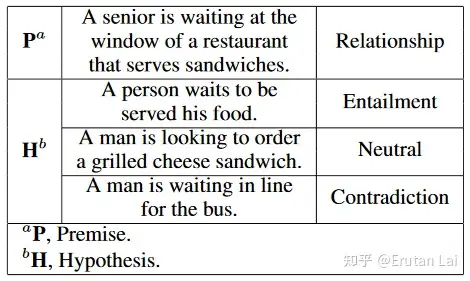
8.文本语义相似性 (Semantic textual similarity)

9.语义分析 (Semantic parsing)

10.话语分析 (Discourse parsing)
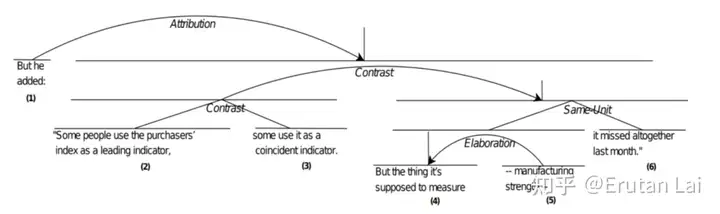
11.文本简化 (Text simiplification)

三、自然语言生成与写作
(五)语言生成 (Generation)
(二十四)文摘 (Summarization)
文本生成任务中的翻译和对话被单独摘出来了,而其它文本生成任务都放在了这里。
关于文本生成,多说两句。因为很多人看到“生成”就会觉得很厉害。因为其它自然语言处理任务大多都是在做分类,比如情感倾向判断(二分类)、实体检测/答案抽取(相当于对每个字/词做分类,判断抽或者不抽,或者组合标签)、分析(parsing,相当于构图,两两节点之间判断是否连边,以及边类型分类)。但实际上,生成也是分类。现在主流的文本生成过程,每次去预测(分类)下一个词应该是什么,即在数千规模的词表(类别标签)上分类,当分类到停止符时就停止生成。
关于文本生成与写作相关的研究方向,主要可以分为以下三个大类:
1. 不同的输入形式的任务。比如数据到文本生成 (Data-to-text generation,给一些主谓宾三元组,生成完整的描述语句,如个人简洁、商品广告)。文本到文本生成 (Text-to-text generation) 比如文本摘要,文本风格迁移(立场转换、情感倾向转换等),故事续写,给定关键词的诗歌生成等。其实还可以有图片到文本的生成,比如看图说话(Image caption),但这种其实算是多模态,计算机视觉和自然语言处理的交叉。
其中,ACL对摘要分得更细一点。比如有抽取式摘要 (Extractive summarization,抽原文中的句子作为摘要,其实不算生成与写作,我只是偷懒放这了),生成式摘要(Abstractive summarization)。还有针对多模态、多语言、多文档、对话等不同格式的摘要(Multimodal/Multilingual/Multi-document/Conversational summarization),给定查询之后的有倾向性的面向查询的摘要 ,(Query-focused summarization),面向长文本的长格式摘要 (Long-form summarization)和面向短文本的句子压缩 (Sentence compression)。
2. 通用的底层技术,比如模型结构 (Model architectures,口袋类),高效模型 (Efficient models,自回归解码,与成千上万的候选词,总是让生成模型很慢),少样本生成 (Few-shot generation),领域迁移 (Domain adaptation),检索增强生成 (Retrieval-augmented generation),推断方法 (Inference methods,我猜是非自回归生成,以及各种多步/可控生成)等等。
3. 评价与分析方面。文本生成的评价不像一般分类任务那样,和标准答案有一点差别就算错。所以,经常需要人工评价 (Human evaluation),自动评价 (Automatic evaluation)的方法也更加复杂。除此之外,对于摘要等任务,事实正确性 (Factuality)、一致性、流畅度等方面的检测和分析 (Analysis)也是不可或缺的。
上面的第二类和第三类,其实和翻译、生成式对话等领域基本上是共通的。
以下是一些具体任务的举例:
1.数据到文本生成 (Data-to-text generation)
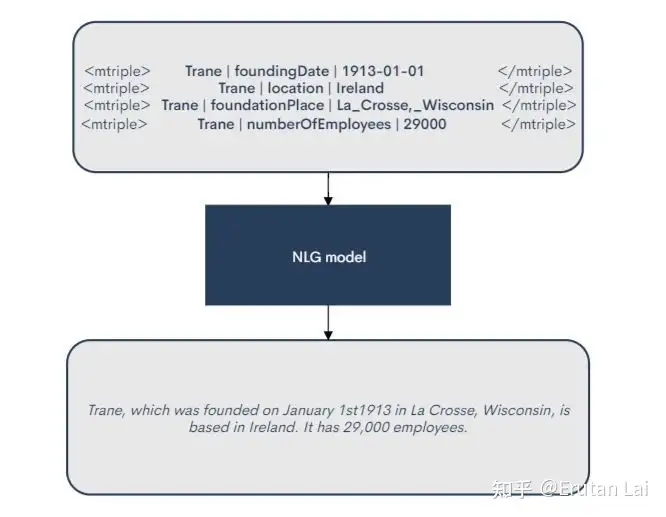
2. 表格到文本的生成,有时和数据到文本的生成很像。

3. 文本风格迁移(情感反转)
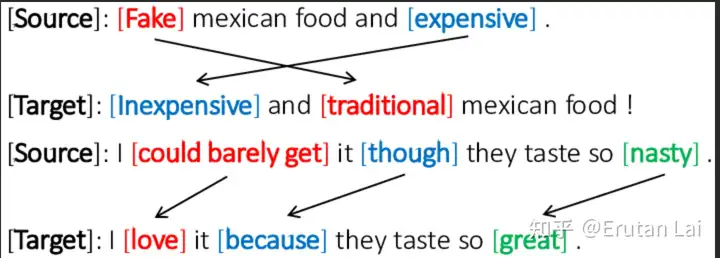
4.抽取式摘要(Extractive summarization)

5.面向查询的摘要 (Query-focused summarization)

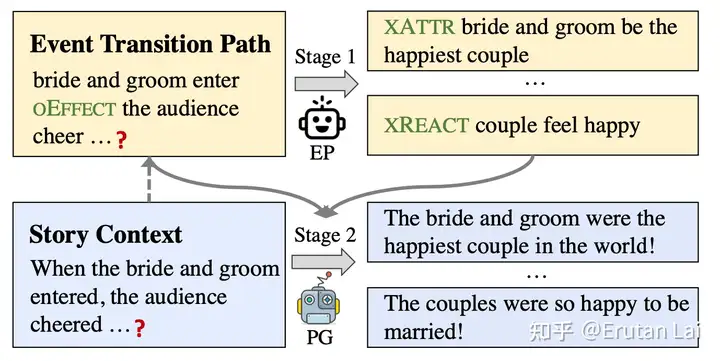
6. inference上的花活:基于规划的多次解码(任务是故事补全)
四、机器翻译
(十四)机器翻译 (Machine Translation)
机器翻译,在国家自然科学基金委的方向划分与ACL 的方向划分中均被独立出来,是独一份的。我觉得原因主要有以下两点:
1. 历史悠久。Warren Weaver 于 1947 年就提出了利用计算机进行语言自动翻译的想法。1954 年,美国乔治敦大学在 IBM 公司协同下,用 IBM-701 计算机首次完成了英俄机器翻译试验(但主要基于词意对齐,没有考虑歧义)。1976 年,加拿大蒙特利尔大学与加拿大联邦政府翻译局联合开发了名为TAUM-METEO的机器翻译系统,提供天气预报服务。这个系统每小时可以翻译6-30万个词,每天可翻译1-2千篇气象资料,并能够通过电视、报纸立即公布,机器翻译正式进入应用时代。
以上信息摘取自网络。
和机器翻译一样历史悠久的NLP任务,还有问答与对话(图灵测试)。不过,问答在商用道路上一直受挫。不知道chatGPT是否会彻底颠覆这一现状。
2. 影响广泛。身边到处都有应用,包括比较成熟百度/谷歌翻译、划屏取词、网页翻译,再到尚未成熟的同传助手、嵌入在AR/元宇宙中的翻译助手。
搜索引擎是自然语言处理中另一个广泛应用的场景。不过,早期搜索引擎主要是信息检索的应用(ad hoc search之类的),不太智能。近年来,QA逐渐结合在搜索引擎中,但并未带来颠覆性的革命。即使是chatGPT,未来可能会成为搜索引擎的一个重要组成部分,但也不太可能完全取代现有的搜索引擎。
机器翻译可以认为是一类特殊的文本到文本生成 (Text-to-text generation)任务,即输入和输出文本之间具有相同的语义,但属于不同的语言。机器翻译中也有一些是面向语音的翻译(Speech translation),不过我感觉很多还是将语音转化为音位/音节(或者由其组成的词格图)之后,再做的处理。直接处理语音信号的工作有但不多。
机器翻译中的通用底层技术、评价与分析上的任务和前面语言生成里面的差不多,这里也不再多说了。比较有特色的是机器翻译有一些更贴合应用的研究角度,比如机器翻译部署和维护 (MT deployment and maintainence),机器翻译的线上运用 (Online adaptation for MT)。
以下是一些机器翻译任务/方法的举例:
1、统计机器翻译与神经网络机器翻译(展示机器翻译任务和基本原理):
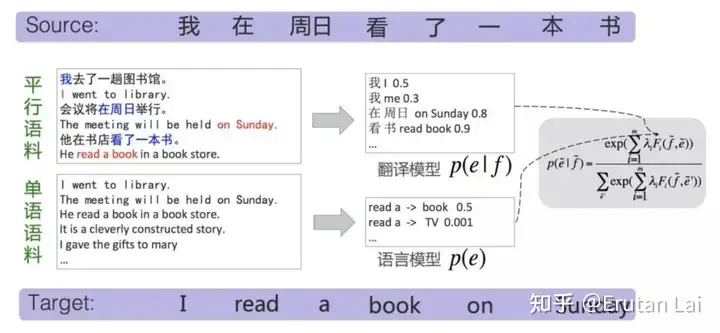
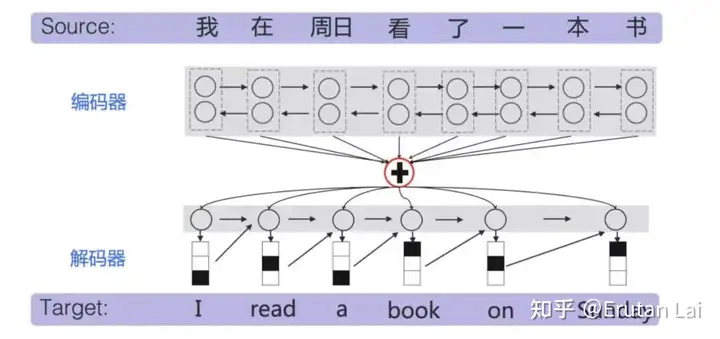
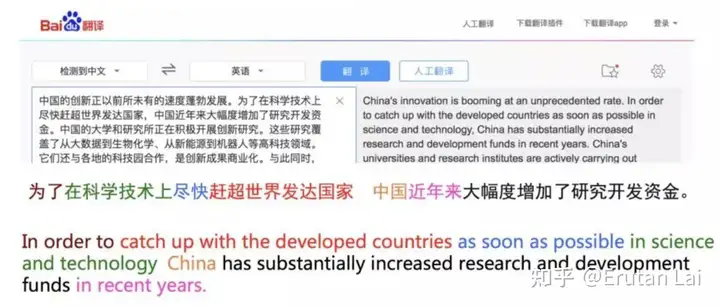
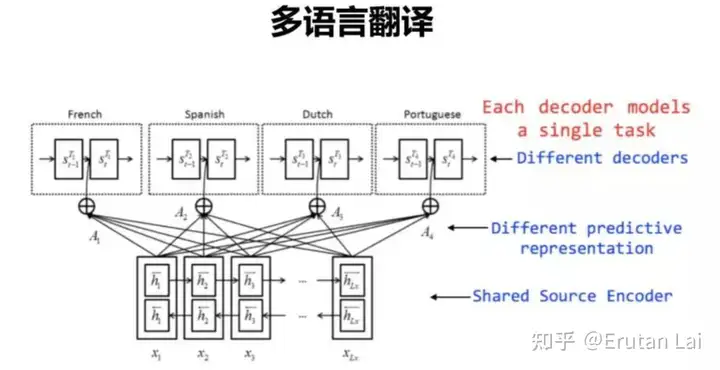
2. 多语言机器翻译 (Multilingual MT)
3. 并行解码和非自回归的机器翻译 (Parallel decoding/non-autoregressive MT)
非自回归机器翻译,也就是说生成过程不是一个词一个词地生成,而是一次性生成所有。挑战包括无法确定对应关系,容易重复、漏翻;生成结果的流畅度低等。
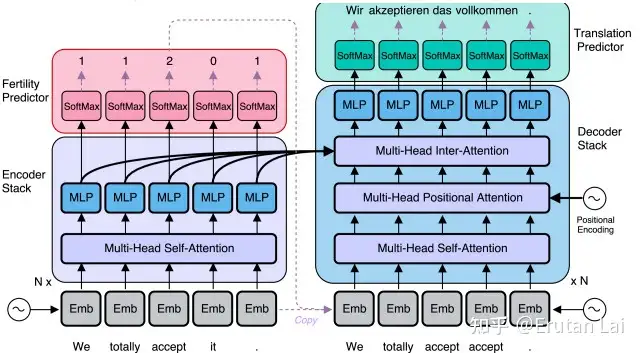
4. 多模态机器翻译(Multimodality MT)
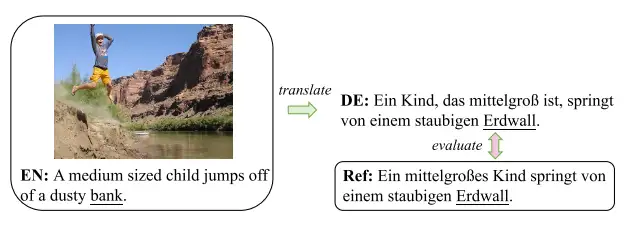

五、面向语言的机器学习
(八)自然语言处理模型的可解释性与分析 (Interpretability and Analysis of Models in NLP)
(十)大模型(Large Language Models)
(十三)自然语言处理中的机器学习 (Machine Learning for NLP)
这里其实和“F0603 机器学习”有交叉。通用机器学习方法在自然语言处理任务上实践时,必然会需要做一些适应性地修改。而我把大模型放到这里,主要是将预训练-精调(或prompt)作为一种机器学习的新范式。实际上,如果针对翻译、问答、信息抽取等任务专门设计的预训练/精调方式,应当归类到具体的任务当中。
具体的研究方向大致可以分成如下几类:
1. 通用机器学习方法在自然语言处理任务上的调整,包括优化方法 (Optimization methods 偏数学?),自监督学习 (Self-supervised learning),少样本学习 (Few-shot learning),强化学习 (Reinforcement learning),多任务学习 (Multi-task learning),迁移学习和领域适应 (Transfer learning / domain adaptation),参数高效的微调方法 (Parameter-efficient finetuning),元学习 (Meta learning 学习如何学习、学习任务而非数据之类的),连续学习 (Continual learning 如何借鉴之前学到的知识并避免遗忘),模型压缩方法 (Model compression methods),对比学习 (Contrastive learning),对抗学习 (Adversarial training),人参与的学习和主动学习 (Human-in-a-loop / Active learning)等。
2. 自然语言处理特定的一些机器学习方法,比如语言表征类的词嵌入 (Word embedding)、表征学习 (Representation learning)、预训练 (Pre-training);比如语言预测时经常遇到的结构化预测 (Structured prediction,典型的是parsing);因为语言的稀疏性(高“质量”的语言数据比图片难获得)产生的数据增强 (Data augmentation)和知识增强 (Knowledge-augmented methods)方法;语言的泛化 (Generalization),特别是组合泛化相关的研究等。
3. 预训练模型,作为一种新兴的机器学习方式,所面临的一些问题比如:具体的应用方式,微调 (Fine-tuning)与提示 (Prompting);安全与可解释相关的话题,伦理 (Ethics),可解释性和分析 (Interpretability/Analysis),安全和隐私 (Security and privacy)等等。
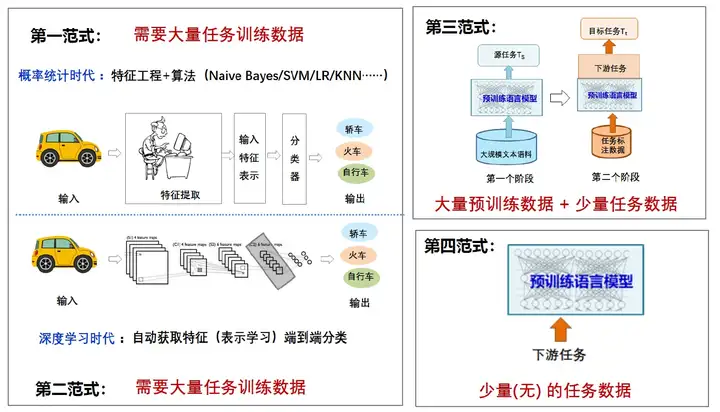
这部分大多都是机器学习中的任务概念,这里也就不多说了,就放一张网传的自然语言处理四大范式的图吧。
六、文本挖掘与信息抽取
(六)信息抽取 (Information Extraction)
(七)信息检索和文本挖掘 (Information Retrieval and Text Mining)
“文本挖掘与信息抽取”也是老牌的自然语言处理任务。如果说“自然语言认知、理解与推理”是从语言学和本文语义的层面识别、建模自然语言,那“文本挖掘与信息抽取”就是从深度语义(结合更大的上下文、结合常识等世界知识的语义)的角度建模自然语言。
信息抽取任务关注于如何从语言中提炼知识,往往以建构结构化知识库作为最终目标。而信息检索任务关注于文档级特征抽取与快速检索。理论上,信息检索任务如果可以基于信息抽取,可以得到更加精确深入的检索结果。然而实际上这并非业界的主流方法。具体而言,信息检索和文本挖掘任务大致可以分成3类。
1. 文本信息抽取任务包括:命名实体识别(Named entity recognition,找到句子中的实体提及并判断实体类别),关系抽取 (relation extraction,判断实体之间的关系),事件抽取 (Event extraction,识别/分类动词形式的事件触发词,以及事件论元),开放信息抽取 (Open information extraction,和上述任务差不多,我理解的是一般没有严格的schema的定义,也没有很多监督,形式和内容上比较open),文档级抽取 (Document-level extraction),多语言抽取 (Multilingual extraction)。
2.知识库的构建任务,比如实体连接和消歧 (Entity linking and disambiguation,将句子中的实体与知识库/ontology中的实体对应起来,并消除歧义,比如判断是哪个李娜),知识库构建 (Knowledge base construction,很多琐碎的点,比如Open IE中提取的关系也需要和知识库对齐,同源异构/异源异构/跨语言知识库合并等)。
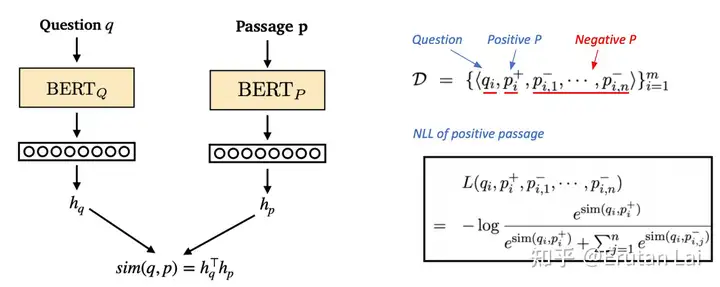
3.信息检索,比如段落检索 (Passage retrieval),稠密向量检索 (Dense retrieval),文档表征 (Document representation),哈希 (Hashing),重排序 (Re-ranking),对比学习 (Constrastive learning)等。
信息检索在ACL中分得比较糙,因为整体而言,信息检索投SIGIR/CIKM之类的会比较多。
信息抽取任务还有一个特点,就是经常做多任务联合学习,比如实体和关系联合抽取(命名实体识别+关系抽取)等。
以下是一些具体任务的举例:
1. 命名实体识别(Named entity recognition)
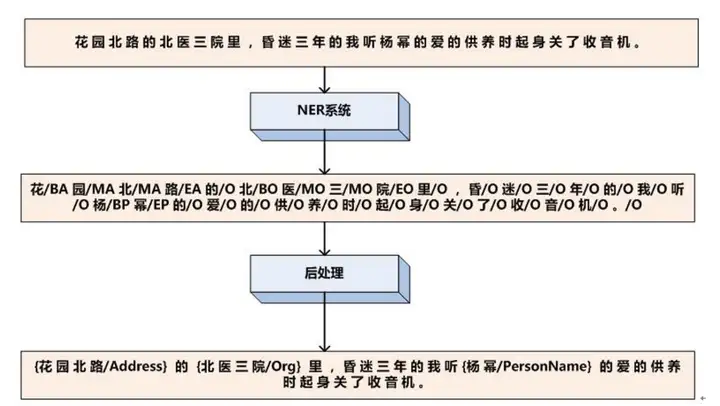
2. 关系抽取 (relation extraction)
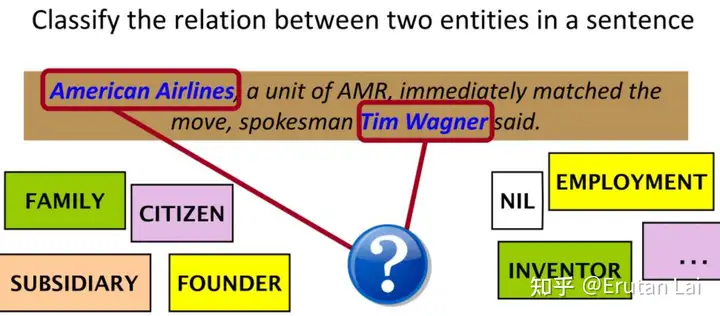
3.事件抽取 (Event extraction)
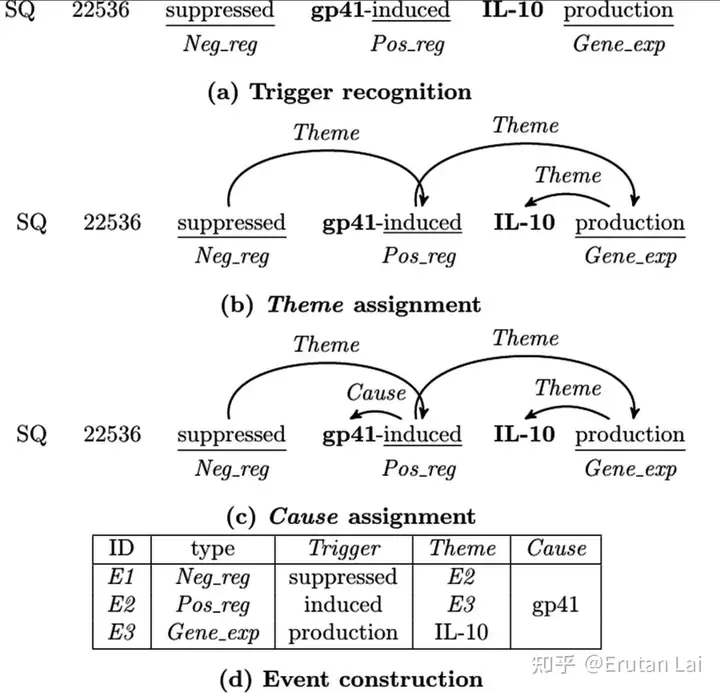
4.开放信息抽取 (Open information extraction)
5.实体连接和消歧 (Entity linking and disambiguation)
6.稠密向量检索 (Dense retrieval)
七、人机对话与问答
(二)对话和交互系统 (Dialogue and Interactive Systems)
(十八)问答 (Question Answering)
前面在谈机器翻译时提到了,问答、对话 和机器翻译一样,也是属于历史悠久、影响广泛的自然语言任务,所以也被单分出来了一类。
实际上,问答和对话所用的方法和前面那些任务是很像的。比如基于语义解析的问答(semantic parsing based QA),以及一些知识库问答(knowledge based QA)的方法和前面的parsing的方法是共通的,并用到信息抽取的一些思路;很多抽取式问答(extractive QA/MRC)、基于候选重排序的问答(Information retrieval based QA/Multiple choice QA)、检索式对话(Information retrieval based dialogue),也是用到了信息抽取、信息检索的技术;生成式对话(generation based dialogue)、问题生成(question generation)以及生成式对话评价方面和文本生成任务之间有很多共性;任务型对话(Task-oriented dialogue)和信息抽取之间关系也非常密切。
问答和对话有什么差别,也是一个经常被问到的问题。我感觉,问答很多时候期待能够获得一个问题的精准解答,所以经常需要结合信息抽取、语义解析、知识库上的操作。问答中的对话式问答,一般也是追问类的,补充背景信息的比较多。对问答的评价,很多时候看的是accuracy,F1-score等精确性的指标。而对话,有些只是闲聊,有些则是关注于完成一定目的(任务型对话、对话推荐)等。更多地关注如何生成让人更感兴趣的内容,让对话更好地进行下去,并完成任务。一些结合知识、情感、persona等的方法,也经常为了辅助这一目的。评价指标经常会看对话的轮数,bleu等文本生成的指标,人工评价等。
问答和对话的研究方向,大致可以分成以下3类:
1. 不同的形式、语境、内容下的问答/对话:比如常识问答 (Commonsense QA)、阅读理解 (Reading comprehension)、多模态问答 (Multimodal QA)、知识库问答 (Knowledge base QA)、多跳问答 (Multihop QA)、生物医学问答 (Biomedical QA)、多语言问答 (Multilingual QA)、对话问答 (Conversational QA)、数学问答 (Math QA)、表格问答 (Table QA)、开放域问答 (Open-domain QA)、口语对话系统 (Spoken dialogue systems)、任务型对话 (Task-oriented Dialogue)、多模态对话系统 (Multi-modal dialogue systems)、互动讲故事 (Interactive storytelling),知识驱动对话 (Grounded dialog)。以及一些相关任务,如对话状态追踪 (Dialogue state tracking),问题生成 (Question generation)。
2. 问答和对话比较关注的深层语义的处理,比如语义分析 (Semantic parsing),对话常识推理 (Commonsense reasoning),逻辑推理 (Logic reasoning),可解释性 (Interpretability)。
3.问答和对话比较关注的基础自然语言处理、机器学习问题。比如少样本问答 (Few-shot QA),对话评价指标 (Evaluation and metrics),偏见和毒性 (Bias/toxity),多语言和低资源 (Multilingual / low-resource),人在环内方法 (Human-in-a-loop)等。
以下是一些具体任务的举例:
- 阅读理解 (Reading comprehension)

2.多跳问答 (Multihop QA)
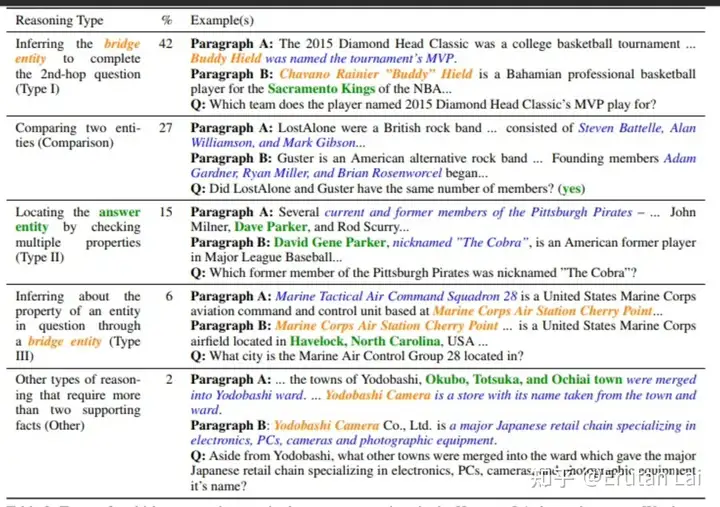
3. 数学问答 (Math QA)
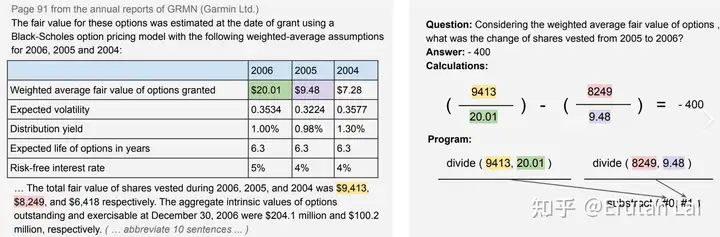
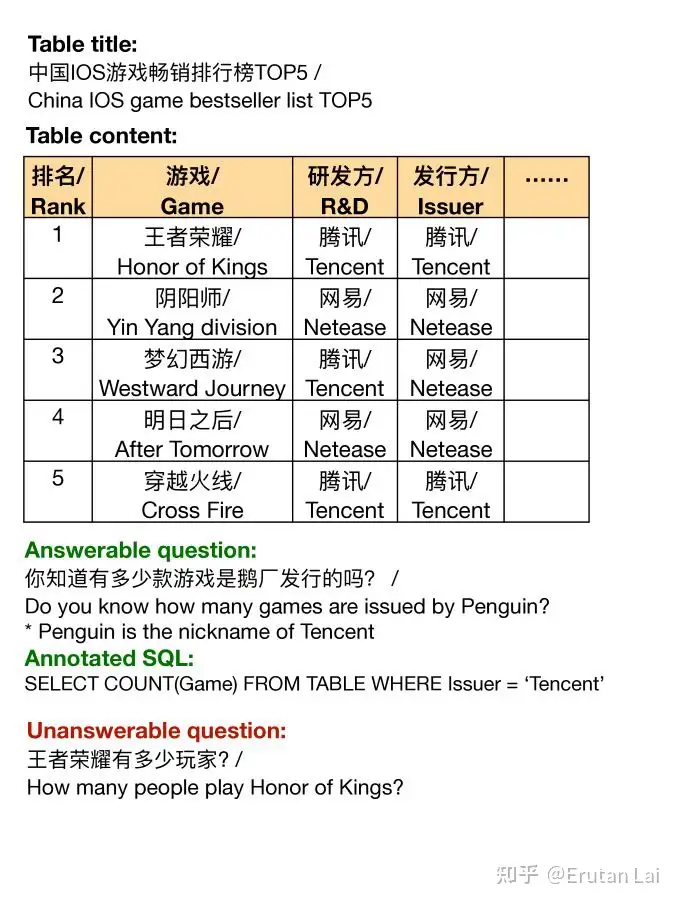
4. 表格问答 (Table QA)
5. 任务型对话 (Task-oriented Dialogue)

6. 情感对话 (Empathetic Dialogue)

7. 知识驱动对话 (Grounded dialog)

8.persona dialogue(也算一种知识驱动)
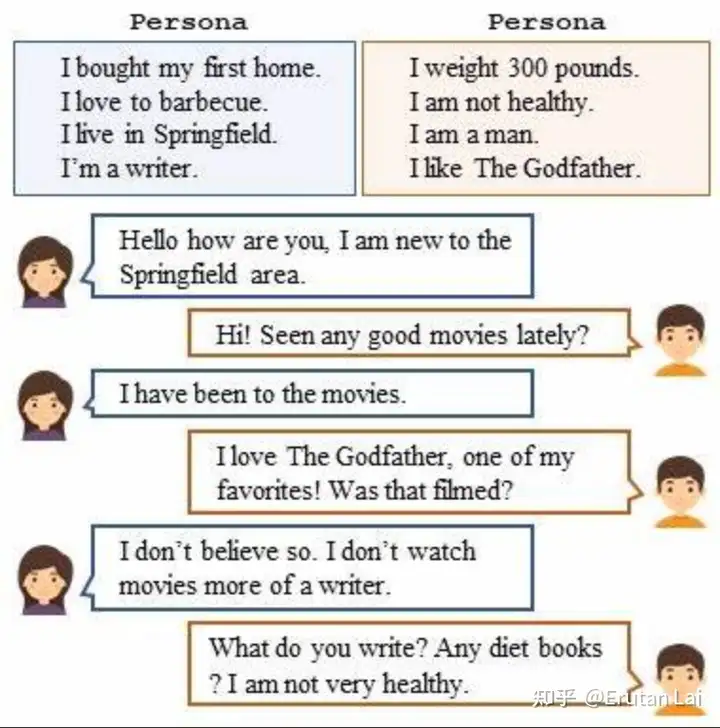
八、情感计算
(二十二)情感分析、文本风格分析和论点挖掘 (Sentiment Analysis, Stylistic Analysis and Argument Mining)
从自然语言处理的学科的角度,情感分析并非一个大的方向。简单的词汇、句子级情感分析,算是“自然语言认知、理解与推理”中的“语义学”的范畴。近年来,情感分析玩出花活,也不过是有一些观点检测 (Stance detection,而非正负的二值情感),aspect based sentiment analysis等任务,也算是在语义学、信息抽取的范畴内。
我猜,国家自然科学基金委将“情感计算”单列出来,主要是考虑到这个任务的应用价值。语言上情感不过是语义的一个方面,但人类对句子的情感倾向非常敏感,俗话说“话要听音,锣鼓听声”。这就导致微博等社交媒体的情感分析,豆瓣影评、商品评论、大众点评等情感分析,新闻评论的情感、立场分析变得尤为重要。如果再上升到舆情分析的层面,就更是国之大器了。同时,也有很多大佬在研究这个方面。
后面的第九项,“社会媒体处理与跨媒体分析”,也是类似的道理。
ACL的“情感分析、文本风格分析和论点挖掘”,其实也包含了情感计算之外的内容,比如论点挖掘相关的,应该属于信息抽取与文本生成,包括论点挖掘 (Argument mining),论证方案和推理 (Argument schemes and reasoning),论点生成 (Argument generation),论点质量评价 (Argument quality assessment,我觉得这个有点计算社会学的感觉,比如庭审辩论分析)。风格分析相关的,我觉得属于文本语义与文本生成,包风格分析 (Style analysis),风格生成 (Style generation)。
我对情感计算并没有很深入的研究,以上主要是我自己的一点理解,如有疏漏在所难免,欢迎指正。
这两篇文章讲的情感分析数据集,我感觉写得都挺好的,就不贴图了。
Top 8 Sentiment Analysis Datasets in 2023research.aimultiple.com/sentiment-analysis-dataset/
尘心:文本分类(情感分析)中文数据集汇总276 赞同 · 25 评论文章
九、社会媒体处理与跨媒体分析
(一)计算社会科学和文化分析 (Computational Social Science and Cultural Analytics)
(九)视觉、机器人等领域的语言基础 (Language Grounding to Vision, Robotics and Beyond)
(二十三)语音和多模态 (Speech and Multimodality)
这个类别我并不懂。我就当社会媒体处理是计算社会科学(实际上,社会媒体只是计算社会学的数据源的一小部分),而跨媒体分析指多模态了。
计算社会科学相关的任务有:人类行为分析 (Human behavior analysis),态度检测 (Stance detection),仇恨言论检测 (Hate speech detection),错误信息检测和分析 (Misinformation detection and analysis),人口心理画像预测 (psycho-demographic trait prediction),情绪检测和分析 (emotion detection and analysis),表情符号预测和分析 (emoji prediction and analysis),语言和文化偏见分析 (language/cultural bias analysis),人机交互 (human-computer interaction),社会语言学 (sociolinguistics),新闻和社交媒体的定量分析 (quantiative analyses of news and/or social media)等。
多模态相关的任务有:视觉语言导航 (Visual Language Navigation),跨模态预训练 (Cross-modal pretraining),图文匹配 (Image text macthing),视觉问答 (Visual question answering),跨模态信息抽取/机器翻译/内容生成 (Cross-modal information extraction/machine translation/content generation),语音识别 (Automatic speech recognition),口语理解/翻译 (Spoken language understanding/translation),语音和视觉 (Speech and vision),口语问答/对话 (QA via spoken queries/Spoken dialog),视频处理 (Video processing)等。
分类比较牵强,我也不太熟悉,这里也就不举例了。
十、其他研究方向
(四)自然语言处理和伦理 (Ethics and NLP)
(十一)语言多样性 (Language Diversity)
(十五)多语言和跨语言自然语言处理 (Multilingualism and Cross-Lingual NLP)
(十六)自然语言处理应用 (NLP Applications)
(十九)语言资源及评价 (Resources and Evaluation)
其它研究方向,主要包括伦理分析,语言变迁研究,自然语言处理在其它学科上的应用等等。我觉得不太容易归类,就都放到这个“其他研究方向”了。这个分类并不严谨,比如“语言资源及评价”、“语言多样性”其实也可以算是“自然语言处理基础理论与方法”。
我把这些领域归到其他研究方向,还有一点考虑是这些领域的“优先级”不高。比如,研究一个问答数据集,更倾向于投稿/提交到“问答”领域,而非“语言资源及评价”。多语言翻译和跨语言问答,也更倾向于算是“机器翻译”与“问答”领域,而非“多语言和跨语言自然语言处理”。一般只有研究的角度不太适合归类到前面的领域,才会算在这些领域。
因此,我就不展开这些任务了。
总结
总结一下,自然语言处理的研究方向,主要包括:(1)对语言的认知和理解过程,如词语的形态学研究、分词、句法、篇章分析等。沿着语言学的路线建构文本语义。(2)语言理解与信息抽取,从提取实体、关系、事件到构建知识库。(3)文本生成,在理解的基础上做摘要、故事补全等。(4)一些重点的应用方向,即机器翻译、问答与对话、情感计算与社会媒体处理。此外,还有一些基础理论和方法,自然语言处理上的机器学习,及自然语言处理在其它领域上的应用等等。