
计算机视觉(Computer Vision)是人工智能领域的一个重要分支。它的目的是:看懂图片里的内容。
本文将介绍计算机视觉的基本概念、实现原理、8 个任务和 4 个生活中常见的应用场景。
计算机视觉为什么重要?
人的大脑皮层, 有差不多 70% 都是在处理视觉信息。 是人类获取信息最主要的渠道,没有之一。
在网络世界,照片和视频(图像的集合)也正在发生爆炸式的增长!
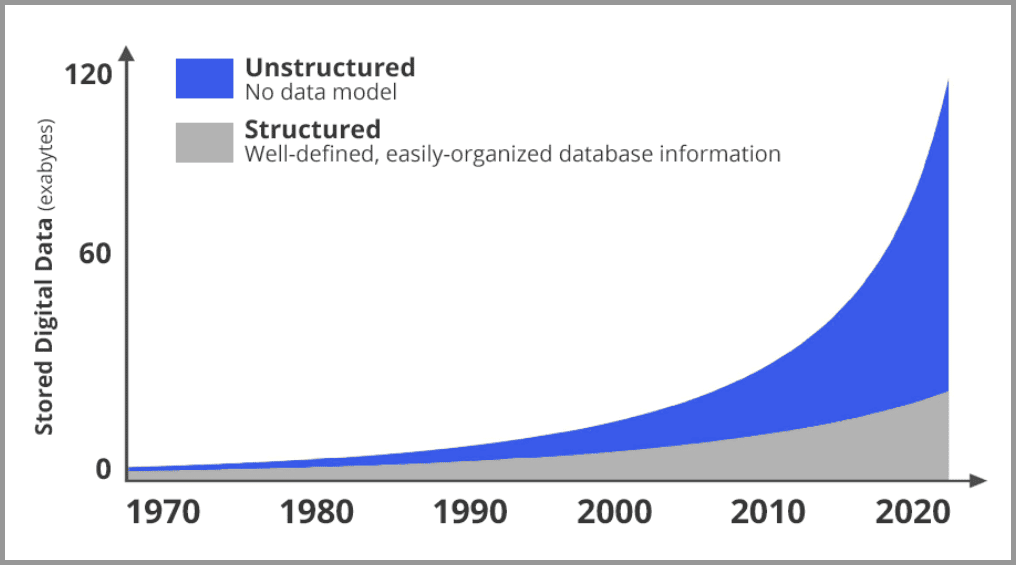
下图是网络上新增数据的占比趋势图。灰色是结构化数据,蓝色是非结构化数据(大部分都是图像和视频)。可以很明显的发现,图片和视频正在以指数级的速度在增长。
而在计算机视觉出现之前,图像对于计算机来说是黑盒的状态。
一张图片对于机器只是一个文件。机器并不知道图片里的内容到底是什么,只知道这张图片是什么尺寸,多少MB,什么格式的。

如果计算机、人工智能想要在现实世界发挥重要作用,就必须看懂图片!这就是计算机视觉要解决的问题。
什么是计算机视觉 – CV?
计算机视觉是人工智能的一个重要分支,它要解决的问题就是:看懂图像里的内容。
比如:
- 图片里的宠物是猫还是狗?
- 图片里的人是老张还是老王?
- 这张照片里,桌子上放了哪些物品?

计算机视觉的原理是什么?
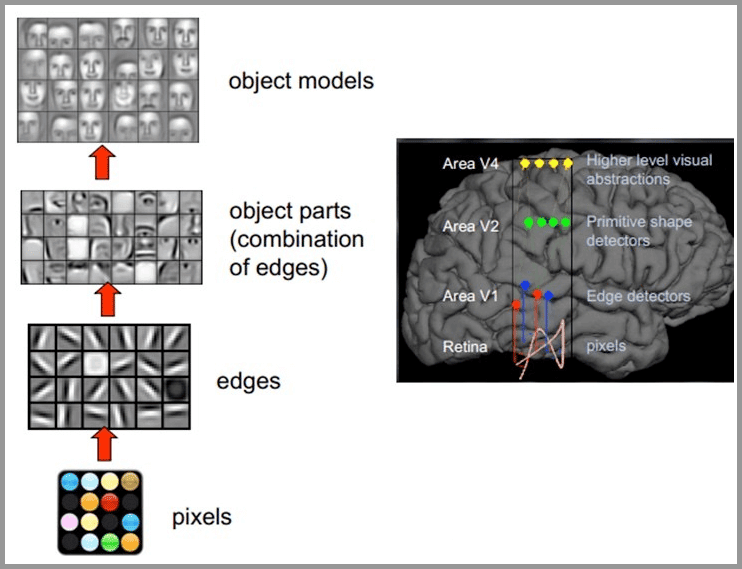
目前主流的基于深度学习的机器视觉方法,其原理跟人类大脑工作的原理比较相似。
人类的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。
https://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-5719288141555693&output=html&h=280&adk=1415798375&adf=4166720225&pi=t.aa~a.487087031~i.45~rp.4&w=732&fwrn=4&fwrnh=100&lmt=1689199040&num_ads=1&rafmt=1&armr=3&sem=mc&pwprc=6509900997&ad_type=text_image&format=732×280&url=https%3A%2F%2Feasyai.tech%2Fai-definition%2Fcomputer-vision%2F&host=ca-host-pub-2644536267352236&fwr=0&pra=3&rh=183&rw=731&rpe=1&resp_fmts=3&wgl=1&fa=27&uach=WyJXaW5kb3dzIiwiMTAuMC4wIiwieDg2IiwiIiwiMTE0LjAuMTgyMy42NyIsW10sMCxudWxsLCI2NCIsW1siTm90LkEvQnJhbmQiLCI4LjAuMC4wIl0sWyJDaHJvbWl1bSIsIjExNC4wLjU3MzUuMjAxIl0sWyJNaWNyb3NvZnQgRWRnZSIsIjExNC4wLjE4MjMuNjciXV0sMF0.&dt=1689210507326&bpp=2&bdt=1940&idt=2&shv=r20230711&mjsv=m202307060101&ptt=9&saldr=aa&abxe=1&cookie=ID%3D1424df0895b62856-22e66da7a7e200c8%3AT%3D1689210506%3ART%3D1689210506%3AS%3DALNI_MajvuCwvLvD_0Yp9m54gtCSNLNgvw&gpic=UID%3D00000c20487607f7%3AT%3D1689210506%3ART%3D1689210506%3AS%3DALNI_Mb_8UcDi5veM4lEhO79CkZ8XrbdNQ&prev_fmts=0x0&nras=2&correlator=6079564842092&frm=20&pv=1&ga_vid=1137281576.1689210506&ga_sid=1689210507&ga_hid=1785100283&ga_fc=1&u_tz=480&u_his=1&u_h=1080&u_w=1920&u_ah=1040&u_aw=1920&u_cd=24&u_sd=1&dmc=8&adx=768&ady=4529&biw=1850&bih=969&scr_x=0&scr_y=727&eid=44759926%2C44759842%2C44759875%2C31075757%2C44788441%2C21065725&oid=2&pvsid=3784554358923216&tmod=2054673499&wsm=1&uas=0&nvt=1&ref=https%3A%2F%2Fcn.bing.com%2F&fc=1408&brdim=0%2C0%2C0%2C0%2C1920%2C0%2C1920%2C1040%2C1865%2C969&vis=1&rsz=%7C%7Cs%7C&abl=NS&fu=128&bc=31&ifi=2&uci=a!2&btvi=1&fsb=1&xpc=G5YNc3qojC&p=https%3A//easyai.tech&dtd=13
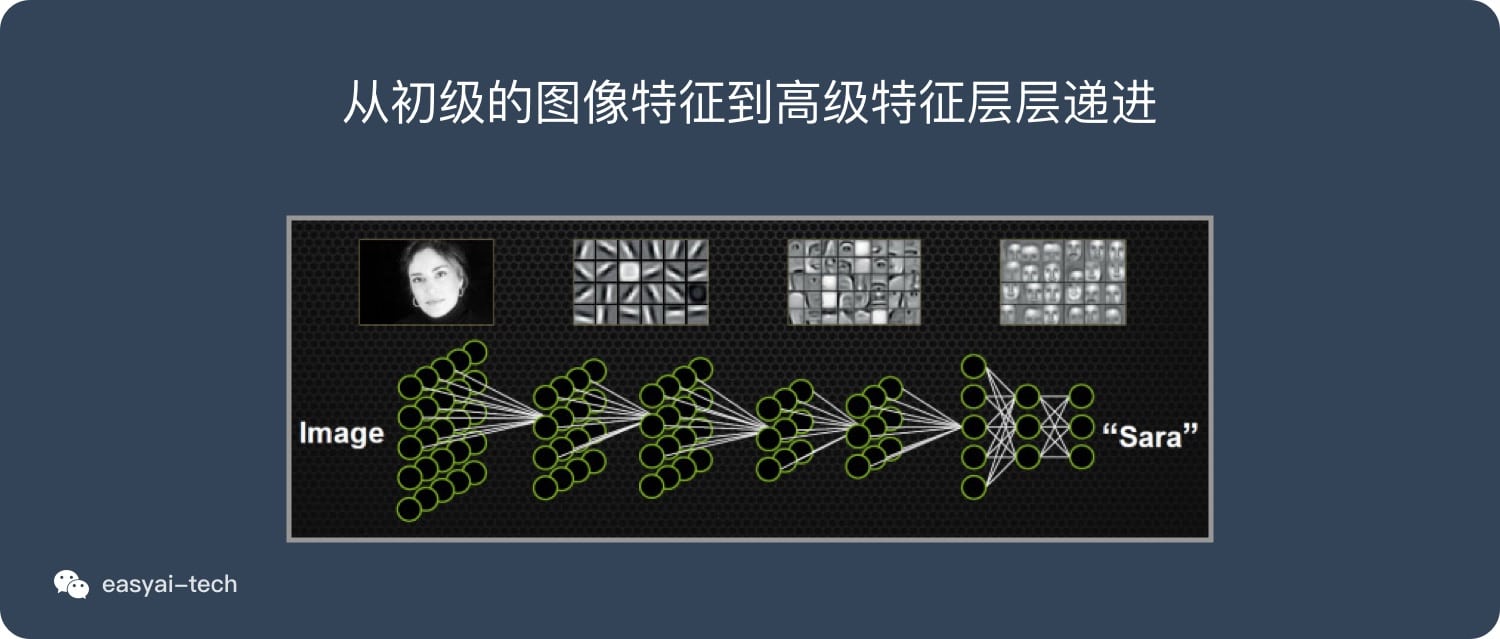
机器的方法也是类似:构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类。
计算机视觉的2大挑战
对于人类来说看懂图片是一件很简单的事情,但是对于机器来说这是一个非常难的事情,说 2 个典型的难点:
特征难以提取
同一只猫在不同的角度,不同的光线,不同的动作下。像素差异是非常大的。就算是同一张照片,旋转90度后,其像素差异也非常大!
所以图片里的内容相似甚至相同,但是在像素层面,其变化会非常大。这对于特征提取是一大挑战。
需要计算的数据量巨大
手机上随便拍一张照片就是1000*2000像素的。每个像素 RGB 3个参数,一共有1000 X 2000 X 3=6,000,000。随便一张照片就要处理 600万 个参数,再算算现在越来越流行的 4K 视频。就知道这个计算量级有多恐怖了。

CNN 解决了上面的两大难题
CNN 属于深度学习的范畴,它很好的解决了上面所说的2大难点:
- CNN 可以有效的提取图像里的特征
- CNN 可以将海量的数据(不影响特征提取的前提下)进行有效的降维,大大减少了对算力的要求
CNN 的具体原理这里不做具体说明,感兴趣的可以看看《一文看懂卷积神经网络-CNN(基本原理+独特价值+实际应用)》
计算机视觉的 8 大任务

图像分类
图像分类是计算机视觉中重要的基础问题。后面提到的其他任务也是以它为基础的。
举几个典型的例子:人脸识别、图片鉴黄、相册根据人物自动分类等。

目标检测
目标检测任务的目标是给定一张图像或是一个视频帧,让计算机找出其中所有目标的位置,并给出每个目标的具体类别。

语义分割
它将整个图像分成像素组,然后对像素组进行标记和分类。语义分割试图在语义上理解图像中每个像素是什么(人、车、狗、树…)。
如下图,除了识别人、道路、汽车、树木等之外,我们还必须确定每个物体的边界。

实例分割
除了语义分割之外,实例分割将不同类型的实例进行分类,比如用 5 种不同颜色来标记 5 辆汽车。我们会看到多个重叠物体和不同背景的复杂景象,我们不仅需要将这些不同的对象进行分类,而且还要确定对象的边界、差异和彼此之间的关系!

视频分类
与图像分类不同的是,分类的对象不再是静止的图像,而是一个由多帧图像构成的、包含语音数据、包含运动信息等的视频对象,因此理解视频需要获得更多的上下文信息,不仅要理解每帧图像是什么、包含什么,还需要结合不同帧,知道上下文的关联信息。
人体关键点检测
体关键点检测,通过人体关键节点的组合和追踪来识别人的运动和行为,对于描述人体姿态,预测人体行为至关重要。
在 Xbox 中就有利用到这个技术。

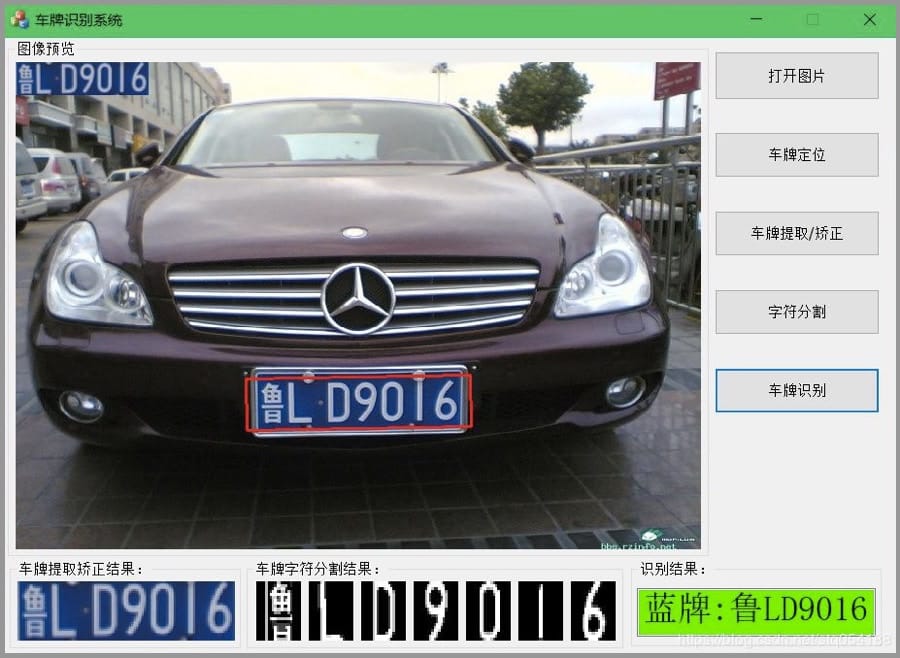
场景文字识别
很多照片中都有一些文字信息,这对理解图像有重要的作用。
场景文字识别是在图像背景复杂、分辨率低下、字体多样、分布随意等情况下,将图像信息转化为文字序列的过程。
停车场、收费站的车牌识别就是典型的应用场景。
目标跟踪
目标跟踪,是指在特定场景跟踪某一个或多个特定感兴趣对象的过程。传统的应用就是视频和真实世界的交互,在检测到初始对象之后进行观察。
无人驾驶里就会用到这个技术。

CV 在日常生活中的应用场景
计算机视觉的应用场景非常广泛,下面列举几个生活中常见的应用场景。
- 门禁、支付宝上的人脸识别
- 停车场、收费站的车牌识别
- 上传图片或视频到网站时的风险识别
- 抖音上的各种道具(需要先识别出人脸的位置)

这里需要说明一下,条形码和二维码的扫描不算是计算机视觉。
这种对图像的识别,还是基于固定规则的,并不需要处理复杂的图像,完全用不到 AI 技术。